Bölüm 2 Regresyon Analizi
Regresyon analizi bir ya da bir kaç değişkenin değerlerinden yararlanarak başka bir değişkenin değerlerini tahmin etmek amacıyla kullanılır. Örneğin bulutların yoğunluğu, havadaki nem miktarı gibi değişkenleri kullanarak ertesi gün yağmurun ne miktarda yapabileceğini tahmin etmek böyle bir analizle mümkündür. Kendi kendine frene basan bir araba yapmak istiyorsanız öndeki arabaya yaklaşma hızı bilgisini kullanarak frene ne kuvvetle basıldığında ne olduğunu (arabanın kaç metre önce durduğu veya duramayıp diğer arabaya çarptığı) tahmin edip arabanın hangi durumda ne kadar frene basması gerektiği arabanın bilgisayarına öğretilebilir. Öğrencilerin ders çalışmaya ayırdıkları süreyi kullanarak sınavdan alacakları puanlar tahmin edilebilir. Bir tedavi yönteminin kanda oluşturduğu değerler kullanılarak hastanın kaç gün içinde iyileşeceği tahmin edilebilir.
Regresyon analizi yapabilmek için bir kereliğine tahmin edici değişken ile tahmin edilmek istenen değişkenin ölçülmüş olması gerekir. Böylece halihazırda elimizde bulunan gerçek veriler üzerinden tahmin yapmaya yarayan istatistiksel denklem üretilir. Bu denklem kullanılarak sonraki çalışmalarda tahmin edilmek istenen değişkenin değerleri üretilir.
Örneğin bulutların yoğunluğu ve yağmurun yağma miktarı ölçülür. Bu ölçümler ile regresyon analiz yapılır. Regresyon denklemi üretilir. Sonraki çalışmalarda sadece bulutların yoğunluğu ölçülür ve yağmurun ne oranda yağacağı tahmin edilir.
Regresyon analizi sonucunda oluşan denklem şöyledir:
\[\begin{equation} \hat{Y} = a+b*X \end{equation}\]
Bu denklemde \(\hat{Y}\) değeri bu denkleme X, a ve b değerlerini koyup hesapladıktan sonra elde edeceğimiz tahmin edilen değeri göstermektedir. a ve b değerleri regresyon analizi yaparken hesaplanan sabit değerlerdir. X değeri ise tahmin edici değişkenin değeridir. Yukarıdaki yağmur örneği için regresyon analizi yapıldığını ve a değerinin 10, b değerinin ise 0.25 olarak elde edildiğini düşünün. Yarın bulutların yoğunluğunun (X değişkeninin değeri) 30 olacağını biliyor olun. Bu durumda değerleri denkleme yerleştirirsek
\[\text{Yağmur yağma oranı} = 10 + 0.25*30\]
olacaktır. Hesaplamayı yaparsak ertesi gün yağmur yağma oranını 17.5 olarak tahmin ederiz.
Regresyon analizinin yapılmış olması bir değişkenin başka bir değişkeni tahmin edeceğinin garantisi değildir. Çoğu kez tahmin edici değişken ile tahmin edilmek istenen değişken arasında regresyon yapılamayacağı bulgusu da elde edilir. Bu nedenle regresyon analizi öncelikle bir değişkenden başka bir değişkenin tahmin edilip edilemeyeceğinin belirlendiği, sonrasında ise denklemin üretildiği bir analizdir. Eğer ilk aşamada regresyon yapılamayacağı anlaşılırsa ikinci aşama olan denklem üretmeye geçilmez.
Bu nedenle regresyon analizinin ilk aşaması tahminle bulunan değerlerin önemli sayılabilecek miktarda regresyon varyansına (aşağıda çok ayrıntılı anlatılacaktır) sahip olup olmadığını belirlemektir. Bunu şekille şöyle gösterebiliriz:
\[Ortalama\underbrace{\underbrace{---------}_\textrm{Regresyon Varyansı}\text{Tahmin Edilen Değerler}{\underbrace{----}_\textrm{Hata Varyansı}}}_\textrm{Toplam Varyans}\text{Gerçek Değerler}\] Gerçek değerlerin ortalamadan uzaklıkları bize toplam varyansı verir. Regresyon varyansı tahmin edilen değerlerin ortalamadan uzaklıklarıdır. Hata varyansı ise Gerçek değerler ile Tahmin edilen değerler arasındaki uzaklıktır. Regresyon analizi sonucunda denklemin kurulabilmesi için regresyon varyansının hata varyansından önemli ölçüde büyük olması istenir. Eğer hata varyansı sıfırsa regresyon varyansı gerçek değerlerin birebir aynısı olmuş demektir. Bu durumda mükemmel bir regresyon modeline sahip olunmuş demektir. Genelde böyle bir durumla karşılaşmayız. Yaygın olarak bir miktar hata varyansı her zaman karşımıza çıkar. Regresyon analizi sonucunda yukarıda bahsedilen regresyon denkleminin kurulabilmesi için regresyon varyansının hata varyansından önemli ölçüde büyük çıkması gerekir. Burada şu soruyla karşılaşırız:
Regresyon denklemi kurabilmek için regresyon varyansı hata varyansından ne kadar büyük olmalıdır?
Acaba 2 katı olması yeter mi? Yoksa 5 kat daha mı büyük olmalıdır? Bu sorunun ilginç bir yanıtı bulunuyor:
Regresyon varyansını hata varyansına böldüğümüzde bir oran buluruz. Bu oran regresyon varyansının hata varyansından kaç kat daha büyük olduğunu gösterir. Örneğin regresyon varyansı 10, hata varyansı 2 olarak elde edilirse \[10/2 = 5 \] yaparak regresyon varyansının hata varyansının 5 katı olduğunu buluruz. Bu orana F değeri denir. Yani \[F=\frac{10}{2}=5\]
Elde edilen bu oran istatistikte F dağılımı olarak bilinen bir dağılıma uygun gidişat sergiler (“Kanıt,” n.d.). F değerinin F dağılımına uygun olması F dağılımını iyi tanıdığımız için değerlendirme kolaylığı getirir. Örneğin F değeri 3.5 çıkarsa F dağılımı tablosundan bakılarak regresyon varyansının önemli ölçüde büyük olup olmadığı kararı alınabilir.
Yukarıda bahsettiğimiz toplam varyans, regresyon varyansı ve hata varyansının tek tek hesaplanması gerekir. Toplam varyans gerçek değerlerin ortalamalarından çıkarılıp, karelerinin alınıp, toplanıp kişi sayısının bir eksiğine bölünmesiyle kestirilir. Regresyon varyansı ise tahmin edilen değerlerin gerçek değerlerin ortalamasından çıkarılıp, karelerinin alınıp, toplanıp, kestirilecek parametre sayısının bir eksiğine bölünmesi ile bulunur. Hata varyansı ise gerçek değerlerin tahmin edilen değerlerden çıkarılıp, karelerinin alınıp kişi sayısından parametre sayısına (basit regresyonda sadece a ve b parametreleri kestirilir) bölünmesi ile bulunur. Yukarıda da söylendiği gibi regresyon varyansı ne kadar yüksekse o kadar iyidir. Çünkü toplam varyansın büyük kısmı regresyon varyansı tarafından yakalanabiliyor demektir.
Buraya kadar karışık gelmiş olabilir. Bir örnekle yaparsak daha anlaşılır olacaktır. Aşağıda sırasıyla:
Verilerin regresyon analizi yapmaya uygunluğunu, bir başka ifadeyle regresyon varyansının yeterince büyük olup olmadığını tespit etmek (bunun için önce a ve b değerleri üretilmelidir)
Regresyon denklemini üretmek ve kullanmak gösterilmiştir.
Hastaların ilaç alınca kanlarında oluşan antikor miktarları onların kaç günde iyileşeceğini tahmin eder mi? Bu soruyu cevaplamak için 4 hastayla bir deney yapalım. Bu 4 hastaya ilaç verelim. İlaçtan sonra kanda oluşan antikor miktarlarını ölçelim ve kaçıncı günde iyileştiklerini yazalım. İşte bu bilgiler bir araştırmacı tarafından toplanmış ve aşağıdaki tabloya yazılmıştır:
| Kaç Günde İyileşti | Kanındaki Antikor | |
|---|---|---|
| Ali | 40 | 3 |
| Veli | 30 | 4 |
| Ayşe | 20 | 7 |
| Fatma | 10 | 8 |
Biz bu 4 hastanın zaten kaç günde iyileştiklerini biliyoruz. Regresyon analizi ile amacımız, iyileşme gün sayısı (Y) ile antikor değerleri (X) arasındaki ilişkiyi kullanarak gün sayılarının tahmini değerleri (Ŷ) ne oluyor bulunabiliyor mu incelemektir. Bunu test edebilmek için Regresyon varyansının hata varyansından önemli ölçüde daha büyük bir varyans olup olmadığını belirlemek durumundayız. Regresyon varyansını kestirebilmek için hastaların kaç günde iyileştiklerinin tahmini değerlerini de bulmak zorundayız.
Regresyon varyansı tahmin edilen değerlerden gerçek değerlerin ortalamasını tek tek çıkartıp, oluşan farkların karelerini alıp, bu karelerin toplamını alıp, bu toplamı tahmin edici değişken sayısına bölerek bulunur. Formülü şöyle yazılabilir:
\[\begin{equation} \text{Regresyon Varyansı} = \frac{\sum(\hat{Y}-\overline{Y})^2}{p-1} \tag{2.1} \end{equation}\]
Bu denklemde \(\sum{}\) toplama işlemi yapılacağını; \(\hat{Y}\) tahmin edilen değerleri; \(\overline{Y}\) gerçek değerlerin ortalamasını göstermektedir. p-1 değeri ise regresyonda analizinde değeri kestirilecek parametre sayısını göstermektedir. Regresyon analizinde a değeri ve b değeri olmak üzere iki parametreyi kestirmeye çalıştığımız için p değeri tek tahmin edici kullanılan analizlerde 2 olacaktır. Eğer iki tahmin edici birden kullanıyorsak iki tane b değeri ve bir tane a değeri kestirmek zorunda kalacağımızdan p değeri 3 olacaktır. Bu formüle göre yukarıda da söylendiği gibi tahmin edilen değerlerin her birisinden gerçek değerlerin ortalaması çıkarılacak, bunların kareleri alınacak, bunlar toplanacak ve parametre sayısının 1 eksiğine bölünecektir. Regresyon varyansı, tahmin edilen değerlerin varyansını göstermektedir.
Çoğu regresyon analizinde tahmin edilen değerler gerçek değerleri birebir tutturamaz. Gerçek değerler ile regresyon ile tahmin edilen değerler arasında farklar olur. Bu farklara hata veya residual (artık) denir. Örneğin gerçek değer 30 iken tahmin edilen değer 30.275 çıkabilir. Bu durumda 0.275’lik fark hata veya residual (artık) olarak isimlendirilir. Hataların da bir varyansı vardır ve aşağıdaki formül ile kestirilmektedir.
\[\begin{equation} \text{Regresyon Hataları Varyansı} = \frac{\sum(Y-\hat{Y})^2}{n-p} \tag{2.2} \end{equation}\]
Bu eşitlikte \(\sum{}\) toplama işlemi yapılacağını, Y gerçek değerleri, \(\hat{Y}\) tahmin edilen değerleri göstermektedir. n kişi sayısını, p ise kestirilen parametre sayısını (a ve b değerleri parametrelerimizdir) göstermektedir. Eşitliğe göre gerçek değerlerden tahmin edilen değerler çıkarılacak, kareleri alınarak toplanacak ve kişi sayısından p değerine (parametre sayısı) bölünecektir. Hata varyansı tahminlerin gerçeklerden farkıdır.
Hata varyansının küçük olması istenir ki regresyon varyansı büyük olsun ve regresyon denklemi üretilebilsin. Regresyon yapılabileceğine \[\frac{\text{regresyon varyansı}}{\text{hata varyansı}}\] oranından karar verdiğimiz için geleneksel olarak regresyon analizinde toplam varyansın hesaplanmasının gereği yoktur. İlgilenenler için toplam varyansla ilgili bir kaç şey söylemek gerekir.
Toplam varyans, gerçek değerlerden ortalamayı tek tek çıkarıp, oluşan farkların karelerini alıp, bu karelerin toplamını alıp, bu toplamı kişi sayısının bir eksiğine bölerek bulunur. Formülü şöyle yazılabilir:
\[\begin{equation} \text{Toplam Varyans} = \frac{\sum(Y-\overline{Y})^2}{n-1} \tag{2.3} \end{equation}\]
Bu denklemde \(\sum{}\) toplama işlemi yapılacağını; Y gerçek değerleri; \(\overline{Y}\) gerçek değerlerin ortalamasını göstermektedir. n değeri ise kişi sayısıdır. Bu formüle göre yukarıda da söylendiği gibi gerçek değerlerin her birisinden gerçek değerlerin ortalaması çıkarılacak, bunların kareleri alınacak, bunlar toplanacak ve kişi sayısının bir eksiğine bölünecektir. Toplam varyans, değerlerin ortalamadan farklılaşma miktarıdır.İstatistiğin geleneksel varyans hesaplama prosedüründe değerlerin ortalamadan farkları alınır. Bu farkların kareleri alınır ve toplanır. Bu kareleri alınmış farklara kareler toplamı denir. Kareler toplamının kişi sayısının bir eksiğine bölünmesi varyansı verir. Fakat regresyon analizinde regresyon varyansı bulunurken elde edilen regresyon kareler toplamı, kişi sayısının bir eksiğine değil kestirilmeye çalışılan parametre sayısının bir eksiğine bölünür. Bu nedenle regresyon varyansı ile hata varyansının toplamı toplam varyansı vermez. Regresyon varyansı ile hata varyansının toplamının toplam varyansı verebilmesi için tüm kareler toplamlarının n-1’e bölünmüş olması gerekir. Regresyon analizinde kareler toplamları n-1’e değil, adına “serbestlik derecesi” denen özel bazı değerlere bölünür. Kareler toplamlarının nasıl bulunacağı, bunların hangi serbestlik derecesine bölüneceği, F değerinin nasıl bulunacağı tek tabloda aşağıda gösterilmiştir.
| Kareler Toplamı | Serbestlik derecesi | Varyans | F | |
|---|---|---|---|---|
| Regresyon | \(\sum(\hat{Y}-\overline{Y})^2\) | p-1 | \(\frac{\sum(\hat{Y}-\overline{Y})^2}{p-1}\) | \(\frac{regresyon varyansı}{hata varyansı}\) |
| Hata | \(\sum(\hat{Y}-Y)^2\) | n-p | \(\frac{\sum(\hat{Y}-\overline{Y})^2}{n-p}\) | |
| Toplam | \(\sum(Y-\overline{Y})^2\) | n-1 | \(\frac{\sum(Y-\overline{Y})^2}{n-1}\) |
Şu soruyu tekrar hatırlayalım: Regresyon varyansı hata varyansından ne kadar büyük olmalıdır ki regresyon yapılabilir kararı alınabilsin? Örneğin toplam varyans 10 iken regresyon varyansı 6, hata varyansı 4 olursa bu iyi bir durum mudur? Hatta regresyon varyansı 5.1, hata varyansı 4.9 çıkarsa bu yeterli büyüklükte bir regresyon varyansı mıdır? Yani bir başka deyişle F değeri kaç çıkarsa regresyon varyansı anlamlı derecede büyüktür kararı alınabilir?
Bu soruların cevabını şöyle verebiliriz: Regresyonu yaparken kaç kişiden veri toplandığı, regresyon analizinin kaç tahmin edici kullanılarak yapıldığı gibi faktörler regresyonu anlamlı bulmak için F değerinin kaç olması gerektiğini belirleyecektir. Biz F değerinin kaç olması gerektiğini F tablosu ismi verilen bir tablodan buluruz. Hesapladığımız F değeri ile Tablodaki F değerini (kritik F) karşılaştırırız. Hesapladığımız F değeri daha büyük çıkarsa regresyonumuzun anlamlı olduğu kararını veririz.
Öyle ise anlıyoruz ki amacımız önce F değerini bulmaktır. Fakat ne ilginçtir ki F değerini bulabilmemiz için önce regresyon denklemini \[(\hat{Y} = a+b*X)\] üreterek tahmin edilen değerleri bulmalıyız. Tahmin edilen değerleri kullanarak regresyonu varyansını tespit etmeli. Bu varyansın yeterince büyük olduğuna karar verirsek \[\hat{Y} = a+b*X\] denkleminin kullanılabilir bir denklem olduğuna karar vermeliyiz.
Şimdi örneğimizi çözerek bilgilerimizi uygulamaya dökebiliriz. Araştırma verilerimizi yeniden hatırlayalım.
| Kaç Günde İyileşti | Kanındaki Antikor | |
|---|---|---|
| Ali | 40 | 3 |
| Veli | 30 | 4 |
| Ayşe | 20 | 7 |
| Fatma | 10 | 8 |
Yukarıdaki formülleri kullanarak işlem yapabilmemiz için örneğin regresyon varyansını kestirmemiz için \(\hat{Y}\) değerlerini bulmamız gerekiyor. \(\hat{Y}\) değerlerini bulabilmek için a ve b değerlerini bilmemiz gerekir. İşte a ve b değerlerini hesaplamak için formüller:
\[\begin{equation} b = \frac{\sum(X-\overline{X})*(Y-\overline{Y})}{\sum(X-\overline{X})^2} \tag{2.4} \end{equation}\]
Bu formülde \(\sum{}\) toplama işlemi yapılacağını; X tahmin edici değişkenin değerlerini; Y tahmin edilmek istenen değişkenin gerçek değerlerini, \(\overline{X}\) X tahmin edici değişkenin ortalamasını, \(\overline{Y}\) tahmin edilmeye çalışılan değişkenin gerçek değerlerinin ortalamasını göstermektedir. Buna göre X değerlerinden teker teker X değerlerinin ortalaması çıkarılacak, aynı işlem Y değerleri için de yapılacak elde edilen bu yeni değerler birbirleriyle çarpılacak ve bu çarpımlar toplanacaktır. Bu toplam, X değerlerinin kendi ortalamalarından farklarının karelerinin toplamına bölünecektir.
a katsayısı için kullanmamız gereken formül ise şöyledir:
\[\begin{equation} a = \overline{Y}-b*\overline{X} \tag{2.5} \end{equation}\]
bu formülde \(\overline{X}\) X değerlerinin ortalamasını, \(\overline{Y}\) Y değerlerinin ortalamasını, b ise yukarıda verilen b denklemi sonucunda elde edilen b değerini göstermektedir. Buna göre b değeri X değerlerini ortalaması ile çapılacak ve elde edilen sonuç Y değerlerinin ortalamasından çıkarılacaktır.
Önce b değerini bulmamız gerektiği için b değeri formülündeki işlemleri yapalım .| Kaç Günde İyileşti (Y) | Kanındaki Antikor (X) | X-X̅ |
X-X̅
| |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Ali | 40 | 3 | 3-5.5 | -2.5 | 40-25 | 15 | -2.5*15 | -37.5 | -2.5² | 6.25 |
| Veli | 30 | 4 | 4-5.5 | -1.5 | 30-25 | 5 | -1.5*5 | -7.5 | -1.5² | 2.25 |
| Ayşe | 20 | 7 | 7-5.5 | 1.5 | 20-25 | -5 | 1.5*-5 | -7.5 | 1.5² | 2.25 |
| Fatma | 10 | 8 | 8-5.5 | 2.5 | 10-25 | -15 | 2.5*-15 | -37.5 | 2.5² | 6.25 |
| Ortalama | 25 | 5.5 | Toplam=-90 | Toplam=17 |
Görüleceği gibi b değeri formülünde bölme işleminin üstü (pay) için -90 değerini elde ettik. Bölme işleminin altı (payda) işlemi için 17 değerini elde ettik böylece
\[\begin{equation} b = \frac{-90}{17} = -5.294 \end{equation}\]
olacak şekilde b değerini elde ettik. Şimdi a değerini bulabiliriz.
\[\begin{equation} a = 25-(-5.294*5.5) = 25-(-29,117) = 54,117 \end{equation}\]
olacak şekilde a değerini elde ettik.
Böylece a ve b değerlerini kullanarak ve X değerlerinden yararlanarak tahmin edilen değerleri bulabiliriz. Regresyon denklemini hatırlayacaksınız:
\[\begin{equation} \hat{Y} = a+b*X \end{equation}\]
Aşağıdaki tabloda tahmin edilen değerler hesaplanarak yerleştirilmiştir.
| Kaç Günde İyileşti (Y) | Kanındaki Antikor (X) | Ŷ | Ŷ | |
|---|---|---|---|---|
| Ali | 40 | 3 | 54.117+(-5.294*3) = | 38.235 |
| Veli | 30 | 4 | 54.117+(-5.294*4) = | 32.941 |
| Ayşe | 20 | 7 | 54.117+(-5.294*7) = | 17.059 |
| Fatma | 10 | 8 | 54.117+(-5.294*8) = | 11.765 |
Bu tabloda \(\hat{Y}\) değerleri tahmin edilen değerlerdir. Şimdi gerçek değer ile tahmin edilen değerler elimizde olduğuna göre regresyon varyansını ve hata varyansını hesaplayıp bu ikisini birbirine oranlayabiliriz. Regresyon varyansı aşağıdaki denklem ile hesaplanabilmekteydi:
\[\begin{equation} \text{Regresyon Varyansı} = \frac{\sum(\hat{Y}-\overline{Y})^2}{p-1} \end{equation}\]
Bu denklemde \(\sum{}\) toplama işlemi yapılacağını; \(\hat{Y}\) tahmin edilen değerleri; \(\overline{Y}\) gerçek değerlerin ortalamasını göstermektedir. p değeri ise regresyon analizinde kestirilecek parametre sayısını (a ve b değerleri) göstermektedir. Başka bir ifadeyle tahmin edilen değerlerden gerçek değerlerin ortalaması teker teker çıkarılarak kareleri alınacak, toplanacak ve kestirilen parametre sayısının (burada ve b olduğundan 2) 1 eksiğine bölünecektir. Aşağıdaki tabloda bu işlem gösterilmiştir.
| Kaç Günde İyileşti (Y) | Kanındaki Antikor (X) | Ŷ | Ŷ-Y̅ | Ŷ-Y̅ | (Ŷ-Y̅)² | |
|---|---|---|---|---|---|---|
| Ali | 40 | 3 | 38.235 | 38.25-25 | 13.25 | 175.562 |
| Veli | 30 | 4 | 32.941 | 32.941-25 | 7.941 | 63.059 |
| Ayşe | 20 | 7 | 17.059 | 17.059-25 | -7.941 | 63.059 |
| Fatma | 10 | 8 | 11.765 | 11.765-25 | -13.235 | 175.165 |
| Ortalama | 25 | Toplam = 476.845 |
Görüleceği gibi regresyon varyansı denkleminin pay bölümünü (Regresyon kareler toplamı) 476.845 olarak hesapladık. Payda bölümü (serbestlik derecesi) ise kestirilen parametre saysının 1 eksiğiydi. Bu örneğimizde kestirilen parametre sayımız denklemdeki a ve b değerleri olduğu için p değerimiz 2-1 = 1 olacaktır. İşlemi gerçekleştirirsek şu sonucu buluruz.
\[\begin{equation} \text{Regresyon Varyansı} = \frac{476.845}{1} = 476.845 \end{equation}\]
Görüleceği gibi regresyon varyansımız 476.845 olarak belirlenmiştir.
Şimdi hata varyansını hesaplayabiliriz:
| Kaç Günde İyileşti (Y) | Kanındaki Antikor (X) | Ŷ | Y-Ŷ | Y-Ŷ | (Y-Ŷ)² | |
|---|---|---|---|---|---|---|
| Ali | 40 | 3 | 38.235 | 40-38.235 | 1.765 | 3.115 |
| Veli | 30 | 4 | 32.941 | 30-32.941 | -2.941 | 8.649 |
| Ayşe | 20 | 7 | 17.059 | 20-17.059 | 2.941 | 8.649 |
| Fatma | 10 | 8 | 11.765 | 10-11.765 | -1.765 | 3.115 |
| Toplam = 23.528 |
Hata kareler toplamını 23.528 olarak hesapladık. Şimdi bu değeri serbestlik derecesine bölerek hata varyansını bulacağız. Hata varyansının serbestlik derecesi n-p’dir. Burada n = 4, p = 2 olduğundan 4-2 = 2 yaparak serbestlik derecesini 2 olarak hesaplıyoruz. Şimdi hata kareler toplamını serbestlik derecesine bölelim:
\[\frac{23.528}{2} = 11.764\]
Görüleceği gibi hata varyansı 11.764 olarak kestirilmiştir.
Şimdi F değerini bulmak için Regresyon varyansını hata varyansına bölmeliyiz: \[F=\frac{\text{Regresyon Varyansı}}{\text{Hata Varyansı}}\]
\[F=\frac{476.845}{11.764}\] \[F= 40.534\] F değerimizi 40.534 olarak kestirdik. Bu değer regresyon varyansının hata varyansından 40.534 kat daha büyük olduğunu bildirmektedir. Bu büyüklük anlamlı bir regresyon vardır demek için yeterli midir? Bunun için F tablosuna giderek bu araştırma koşullarında (regresyon varyansı ve hata varyansı serbestlik derecelerini kullanarak) kritik F değerini bulmak gereklidir. Kritik F değeri anlamlı regresyon vardır kararı almak için gerekli minimum F değeridir. Aşağıda regresyon varyansı için 1, hata varyansı için 2 serbestlik derecesi koşulunda kritik F değerini bulmaya yardımcı tablo eklenmiştir.
 .
.
Bu tabloda df1 yazan regresyon varyansı serbestlik derecesi, df2 yazan ise hata varyansı serbestlik derecesini ifade eder. Bizim örneğimizde sırasıyla bu değerler 1 ve 2’dir. O nedenle 1 ve 2’nin kesiştiği yere baktığımızda 18.51 değerini görürüz. Bu değer bu koşullar altında regresyon varyansının önemli olduğuna karar vermek için elde edilmesi gereken minimum F değeridir. Bizim araştırmamızda hesapladığımız F değeri 40.334’tür ve kritik değer 18.51’den büyüktür. O zaman bu hesaplamamızdaki regresyon varyansı anlamlı derecede büyük bir varyansa sahiptir.
Genelde regresyon, hata ve toplam varyansı bildiren istatistik programları aşağıdaki gibi bir tablo sunarlar.
 .
.
Bu tablonun adının ANOVA tablosu olmasının sebebi ANOVA’nın (ANalysis Of VAriance) varyansları birbirine oranlayan bir analiz olması ve regresyon analizinde de sonuçta regresyon varyansını hata varyansına oranlamanın gerçekleştiriliyor olmasıdır. Tabloda SUm of Squares yazan bölüm Kareler toplamıdır. Varyans hesaplaması yaparken değerlerin ortalamadan farklarının karelerinin toplamıdır. df ise serbestlik derecesidir. Kareler toplamı bu serbestlik derecesine bölünür. Mean Square (Kareler ortalaması) ise varyans değeridir. Regresyon Mean Square değeri Regresyon varyansını gösterir. Residual (artık veya Hata diye çevrilebilir) Mean Square değeri ise tahmin hatalarının varyansıdır. Regresyon varyansı hata varyansına bölündüğünde F değerini verir. Görüleceği gibi elde hsapladığımız tüm değerleri bilgisayar programları da aynı şekilde hesaplayarak tablolar halinde sunarlar. Bu tabloda p olarak gösterilen değer ise hesaplanan F değerinin F dağılımında bulunduğu konumunun dağılımın yüzdesel toplamının ne kadarına denk geldiğidir. Bunu daha iyi ifade etmek gerekirse şöyle anlatabiliriz. Her istatistiksel analiz bir değer üretir. Örneğin t testi t değeri üretir Anova F değeri üretir. Korelasyon r değeri üretir. Kay-kare X değeri üretir. Bu değerlerin bir dağılımı vardır. Örneğin F dağılımı vardır, veya t dağılımı vardır. Bu dağılımlarda yer alan değerlerin gerçekleşme ihtimalleri dağılımın yapısı bildindiği için kolayca tespit edilebilir.
O halde a ve b değerlerini kullanarak regresyon denklemi oluşturabiliriz.
Regresyon denklemimiz şöyle olacaktır:
\[\text{Kaç günde iyileşecek} = 54.117 + (-5.294*\text{Kanındaki antikor miktarı})\] Böylece bir kişinin kanındaki antikor miktarını bilirsek a ve b değerlerinden yararlanarak onun kaç günde iyileşeceğini tahmin edebiliriz.
Örneğin bir kişinin kanındaki antikor miktarının 10 olduğunu bilirsek:
\[\text{Kaç günde iyileşecek} = 54.117 + (-5.294*10) = 54.117-52.94 = 1.17\] Görüleceği gibi bu hasta 1.17 günde iyileşecektir.
Peki bu regresyon tahminleri ne oranda başarılı olmaktadır. Hatırlarsanız hesaplamamız sırasında elde edilen tahmin edilen değerler gerçek değerlere birebir benzemedi fakat çok da uzak sayılmazdı. Regresyon analizinde tahminlerin ne kadar başarılı olduğu \(R^2\) değeri ile belirlenmektedir. Aşağıda \(R^2\) formülü verilmiştir:
\[R^2 = 1-\frac{\text{Hata Kareler Toplamı}}{\text{Toplam Kareler Toplamı}}\] Bu formülün 1’den sonraki kısmı hata kareler toplamının toplam kareler toplamı içindeki oranını verecektir. Burada kareler toplamı ile kastedilen bu yazının başından bu yana hesapladığımız fark alarak karesini almak sonra da bu karelerin toplanmasını ifade etmektedir. Elde edeceğimiz bu oranı 1’den çıkararak hatalardan arınık oranı buluruz. Bu oran bize regresyon işleminin hatalardan arınıklık derecesi hakkında bilgi verir. Bu nedenle \(R^2\) değeri aynı zamanda bir regresyon modeli uyumluluk testi olarak da kabul edilebilir. Biz buna goodness of fit (uyum iyiliği) ismini de veriyoruz. Gelin bizim örneğimizdeki \(R^2\) değerini hesaplayalım:
Denklemdeki Hata Kareler Toplamı formülü şöyledir:
\[\begin{equation} \text{Hata Kareler Toplamı} = \sum(Y-\hat{Y})^2 \end{equation}\]
Bu formülde Y gerçek değerleri, \(\hat{Y}\) ise regresyon analizi sonucunda elde edilen tahmin değerlerini göstermektedir. Bu değeri daha önce yukarıdaki regresyon varyansını hesapladığımız tabloda hesaplamıştık ve 23.528 olarak bulmuştuk.
Denklemdeki toplam kareler toplamı formülü ise şöyledir:
\[\begin{equation} \text{Toplam Kareler Toplamı} = \sum(Y-\overline{Y})^2 \end{equation}\]
Bu formülde Y gerçek değerleri, \(\overline{Y}\) ise gerçek değerlerin ortalamasını ifade etmektedir. Toplam kareler toplamı gerçek değerlerin kendi ortalamalarından uzaklıklarının karelerinin toplamıdır. Daha önce bu kareler toplamını hesaplamamıştık. Şimdi aşağıdaki tabloda sırasıyla toplam kareler toplamını hesaplayalım.
| Kaç Günde İyileşti (Y) | Kanındaki Antikor (X) | Y-Y̅ | Y-Y̅ | (Y-Y̅)² | |
|---|---|---|---|---|---|
| Ali | 40 | 3 | 40-25 | 15 | 225 |
| Veli | 30 | 4 | 30-25 | 5 | 25 |
| Ayşe | 20 | 7 | 20-25 | -5 | 25 |
| Fatma | 10 | 8 | 10-25 | -15 | 225 |
| Ortalama | 25 | Toplam = 500 |
Görüleceği gibi toplam kareler toplamı 500 olarak elde edildi. Bu toplam kareler toplamı. değerlerin ortalamadan uzaklıklarının karelerinin toplamıdır. Bu değer varyansın hesaplanmasına giden yolda ilk duraktır. Şimdi hata kareler toplamı ile toplam kareler toplamını kullanarak \(R^2\) değerini hesaplayalım:
\[R^2 = 1-\frac{\text{23.528}}{\text{500}}\] Bölme işlemini yaptığımızda sonuç şuna dönüşür:
\[R^2 = 1-0.047056\]
Çıkarma işlemini de yaparsak \(R^2\) değeri aşağıdaki gibi bulunur:
\[R^2 = 0.952944\]
\(R^2\) değeri 0.952 olarak bulunmuştur. \(R^2\) değerinin en fazla 1 olabileceğini farketmişsinizdir. Eğer hata kareler toplamı sıfır ise \(R^2\) değeri 1 olur. Hata kareler toplamının sıfır olabilmesi için regresyonla elde edilen tahmin değerlerinin gerçek değerlerle birebir örtüşmesi gerekir. \(R^2\)’nin 1’den düşük değer alması hata kareler toplamının artmış olması ile mümkün olabilir. Hata kareler toplamının artması için ise tahminle elde edilen değerlerin gerçek değerlerden uzaklaşması gerekir. Buradan yola çıkarsak \(R^2\) tahminlerin gerçek değerlere yakınlık ölçüsüdür. \(R^2\) büyüdükçe tahminler gerçek değerlere yakın demektir. Düşükse tahminler gerçek değerlerden uzaklaşıyor demektir. Bu nedenle çoğu araştırmacı \(R^2\) değerini regresyonun uyum iyiliği ölçüsü olarak kullanır. Fakat \(R^2\) kullanarak birden çok regresyon analizini karşılaştırmak mümkün değildir.
Yukarıda \(R^2\) değeri hesaplanırken kareler toplamlarını oldukları haliyle kullandık. Kimi araştırmacılar bunun doğru olmayabileceğini, kareler toplamlarının kendi serbestlik derecelerine bölünerek kullanılması gerektiğini düşünürler. Bunun en önemli gerekçesi sonradan göreceğimiz “regresyona birden çok tahmin edici ekleyince” artan \(R^2\) değerini gerçeğe daha yakın hesaplama düşüncesidir. Ayrıca bazı araştırmacılar kareler toplamları yerine kareler toplamlarını serbestlik derecelerine bölerek varyansları elde etme ve daha yansız bir \(R^2\) tahmini oluşturmak isterler. Bunun için adına düzeltilmiş (adjusted) \(R^2\) denen \(R^2\) değeri hesaplanır. Formülü ise şöyledir:
\[\text{Düzeltilmiş R²} = 1-\frac{\text{Hata Kareler Toplamı/(n-p)}}{\text{Toplam Kareler Toplamı/(n-1)}} = 1-\frac{\text{Hata Varyansı}}{\text{Toplam Varyans}}\] Bu formülde n kişi sayısını, p ise parametre sayısını ifade eder (regresyonda a ve b olmak üzere iki parametre kestirdiğimizi unutmayın). Yukarıda hata kareler toplamını 23.528 olarak bulduğumuzu, toplam kareler toplamını ise 500 olarak bulduğumuzu hatırlayacaksınız. Bu değerleri forüle yerleştirerek düzeltilmiş (adjusted) \(R^2\) değerini bulabiliriz:
\[\text{Düzeltilmiş R²} = 1-\frac{23.528/(4-2)}{500/(4-1)} = 1-\frac{11.764}{166.667}= 1 - 0.023528 = 0.9294\]
Yukarıda bulduğumuz bu \(R^2\) değerine düzeltilmiş (adjusted) \(R^2\) denir. Çünkü hesaplama yapılırken hata varyansı ve toplam varyansı bulurken kareler toplamlarını n-1’e değil yukarıda anlatılan kendilerine ait serbestlik derecelerine bölerek bulduk.
Görüleceği gibi düzeltilmiş (adjusted) \(R^2\) değeri geleneksel \(R^2\) değerinden biraz daha düşük (veya ona eşit) çıkma eğilimindedir. Geleneksel \(R^2\) değeri hata kareler toplamını n-1’e (büyük bir değere) bölerek daha küçük bir hata varyansı elde edilmesine yol açar. Düzeltilmiş (Adjusted) \(R^2\) değeri ise hata kareler toplamını n-p (p=parametre sayısı) değerine (n-1’e göre daha küçük bir değere) bölerek hata varyansınının daha büyük çıkmasına yol açar. Bu da daha küçük bir regresyon varyansı demektir. Düzeltilmiş (Adjusted) \(R^2\) değeri modele parametre eklendikçe (mesela iki tane tahmin edici değişken kullanıldığında bir tane a iki tane b değeri olmak üzere toplam 3 parametre ortaya çıkacaktır) hata varyansını büyütür. 4 kişiden veri topladığımız yukarıdaki iyileşme gününü tahmin etme çalışmasının verileriyle örnek yapalım:
\[\text{Geleneksel Hata varyansı} = \frac{\text{Hata Kareler Toplamı}}{(n-1)} = \frac{23.528}{4-1} = \frac{23.528}{3}=7.84\] \[\text{Düzenlenmiş Hata varyansı} = \frac{\text{Hata Kareler Toplamı}}{n-p} = \frac{23.528}{4-2} =11.764\] Görüleceği gibi düzenlenmiş hata varyansı daha yüksek hesaplandı. Gelin verilere bir kişi ve bir tahmin edici değişken daha katalım ve 5 kişiden veri toplandığını düşünelim. Bu 5. kişi Fatma ile birebir aynı değerlere sahip olsun. Böylece Fatma’nın kareler toplamına olan etkisini bir kere daha ekleyerek kolayca hata kareler toplamını bulabiliriz (Bu hayali örnekte eklenen yeni değişkenin kareler toplamına hiç bir etkisi olmadığını varsayın). Bu durumda hata Kareler toplamı = 23.528+3.115 = 26.643 olacaktır. n ise 5’e yükseldiğinden geleneksel yönteme göre hesaplanacak yeni hata varyansı 26.643/4 = 6.66 olacaktır. Düzenlenmiş hata varyansı ise p değeri 3 olacağından (bir tane a değeri iki tane b değeri oluşacağından) 24.643/5-3 = 12.3215 olacaktır. Görüleceği gibi regresyon analizine yeni tahmin ediciler katılması durumunda geleneksel hata varyansı buna daha az tepki vermektedir. Zaten unutulmaması gerekir ki geleneksel hata varyansı hesaplama yönteminde bölen n-1 iken düzeltilmiş hata varyansı hesaplamada n-p’dir. n-p’nin hemen her zaman n-1’den küçük olacağı düşünüldüğünde düzeltilmiş varyansın her zaman daha büyük olacağı, bunun da daha düşük \(R^2\) değerine yol açacağı görülebilir.
Şimdi regresyonun heyecan verici başka bir boyutuna bakalım. Gerçek değerler ile tahmin edilen değerleri geometrik olarak gözlemleyelim:
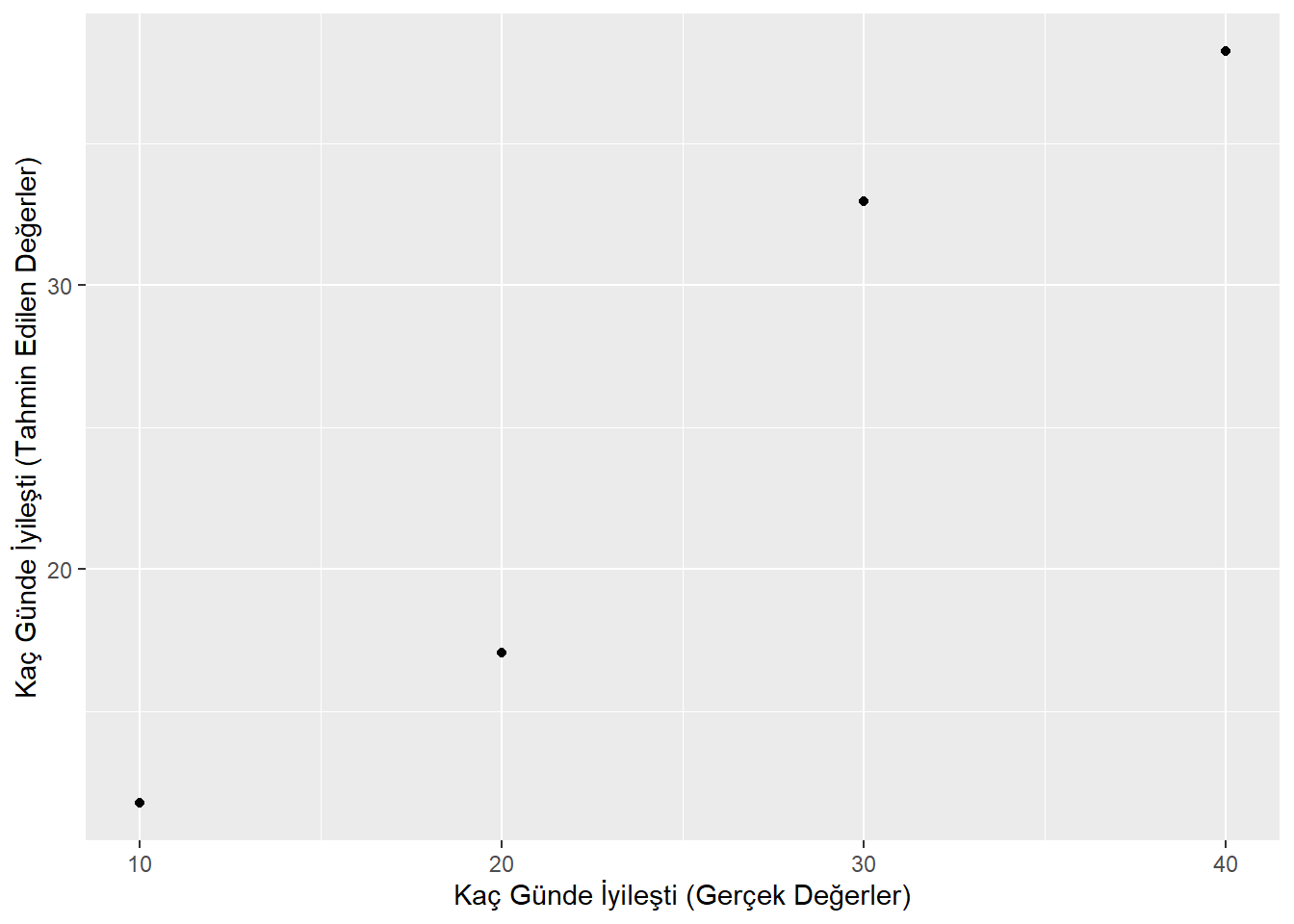
Görüleceği gibi noktalar dümdüz bir doğrunun üzerine oturmuş gibi görünmüyorlar. Çünkü gerçek değerler ile tahminle elde edilen değerler bir miktar farklılık gösteriyor. Eğer gerçek değerler ile tahmin edilen değerler birebir aynı olsaydı şu grafiği elde ederdik:

Şimdi tahminlerimizin grafiğini tekrar çizelim fakat tahmin hatalarımızı görünür hale getirelim:
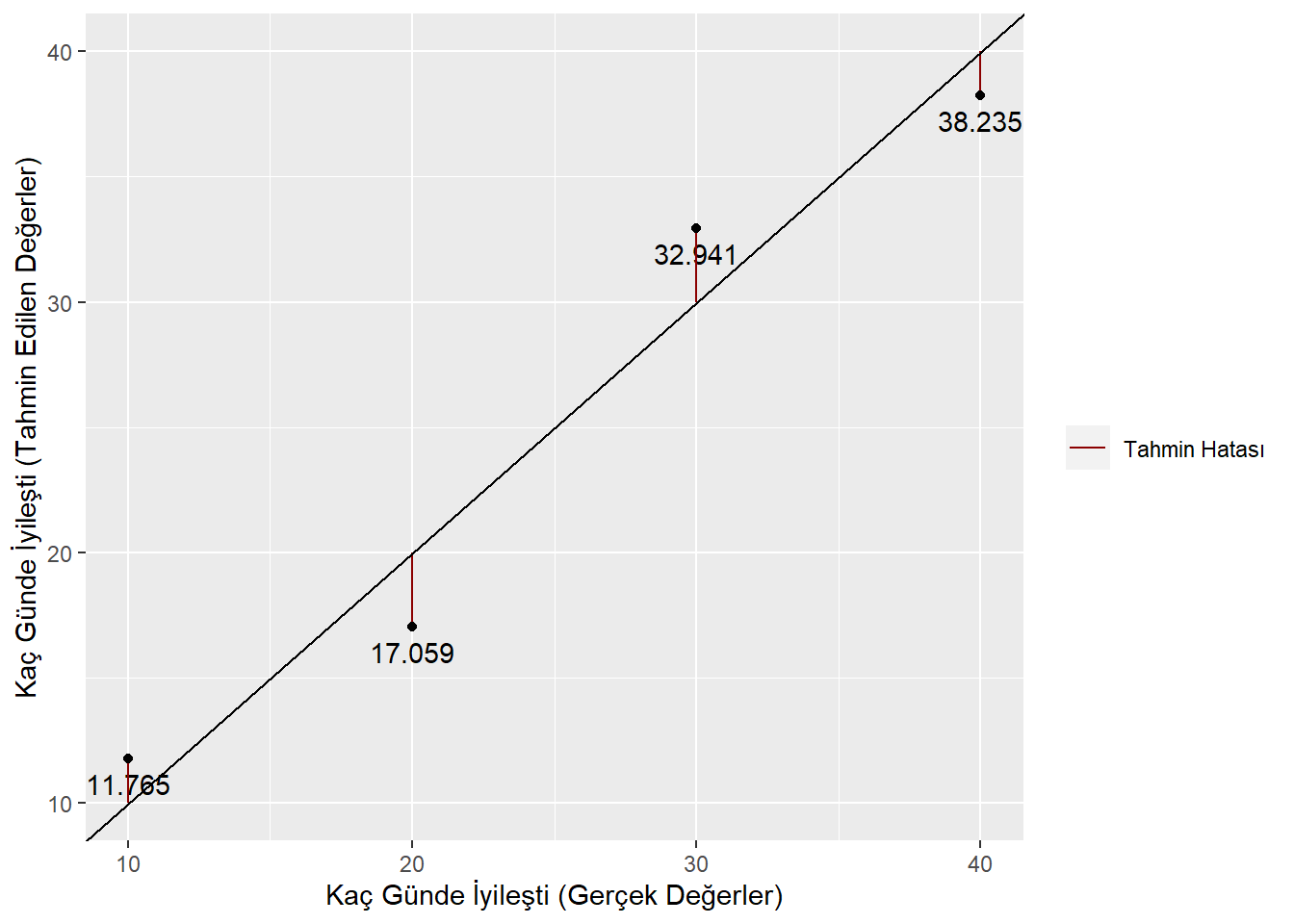
Görüleceği gibi tahmin edilen değerler %100 doğru tahminde bulunsaydık oluşacak olan çizginin biraz üstünde veya altında kalıyorlar. Biz hatırlarsanız \(R^2\)’yi 0.929 olarak hesaplamıştık. \(R^2\) yüzde olarak okunabilen bir değerdir ve tahminlerimizin doğruluk oranının %92.9 olduğunu söylemektedir. Tahmin hatalarımızın toplamı da ilginç bir yapı sergilemektedir. Daha önce görmüştük ama şimdi tahmin hatalarımızı bir tabloda tekrar görelim:
| Gerçek Değer | Regresyonla Tahmin Edilen Değer | Tahmin Hatası | |
|---|---|---|---|
| Ali | 40 | 38.235 | 1.765 |
| Veli | 30 | 32.941 | -2.941 |
| Ayşe | 20 | 17.059 | 2.941 |
| Fatma | 10 | 11.765 | -1.765 |
İlginçtir bir kişide gerçek değerden fazla yönde tahmin yapıldıysa diğer bir kişide tam tersi yönde ve aynı miktarda hata yapılmış görünmektedir. Örneğin Ali için 1.765 puan fazladan tahmin yapılmışken Fatma için 1.765 puan az tahmin yapılmıştır. Bu durum tahmin hatalarının toplamının 0 çıkmasına yol açan önemli bir durumdur. Tüm regresyon analizlerinde tahmin hatalarının toplamı sıfırdır.
Bunun yol açtığı önemli bir durum vardır. Anlamlı bir regresyon varyansına sahipsek gerçek değerlerin ortalaması ile tahminle elde edilen değerlerin ortalaması birbirine benzer olacaktır. Tablodan doğrulayalım:
| Gerçek Değer | Regresyonla Tahmin Edilen Değer | Tahmin Hatası | |
|---|---|---|---|
| Ali | 40 | 38.235 | 1.765 |
| Veli | 30 | 32.941 | -2.941 |
| Ayşe | 20 | 17.059 | 2.941 |
| Fatma | 10 | 11.765 | -1.765 |
| Toplam | 100 | 100 | |
| Ortalama | 25 | 25 |
Bilindiği gibi nicel araştırmalarda ana ilgi konusu ortalamadır. Öyle görünüyor ki regresyon sayesinde tahmin edilen değerlerin ortalaması gerçek değerlerin ortalamasını elde etmemize yardımcı olmaktadır. Fakat gerçek değerlerin standart sapması ile tahmin edilen değerlerin standart sapması \(R^2\) = 1 olmadıkça aynı çıkmayacaktır. Regresyon varyansının değeri toplam varyansın değerine eşit olursa regresyonla elde edilen tahminlerin standart sapması gerçek değerlerin standart sapmasına birebir eşit olur. Peki tahminle elde edilen değerlerin standart sapması gerçek değerlerin standart sapmasına eşit olmazsa ne olur? Böyle bir durumda tahmin edilen deeğerler kullanılarak yapılacak başka analizler yanlı (biased) olur. Örneğin kadınların ve erkeklerin tahmin edilen değelerini kullanarak kadın ve erkeklerin ortalamaları arasında anlamlı farklılık olup olmadığı t testi ile karşılaştırılacak olsun. İşte veriler:
| Gerçek Değer | Grup verileri | Regresyonla Tahmin Edilen Değer | Regresyona Dayalı Grup verileri | |
|---|---|---|---|---|
| Ali | 40 | 38.235 | ||
| Veli | 30 | X̅erkek=35; \(s^{2}\)erkek=50 | 32.941 | X̅erkek=35.59; \(s^{2}\)erkek=14.01 |
| Ayşe | 20 | 17.059 | ||
| Fatma | 10 | X̅kız=15; \(s^{2}\)kız=50 | 11.765 | X̅kız=14.41; \(s^{2}\)kız=14.01 |
Bilindiği gibi bağımsız gruplar için t testinin formülü şöyledir:
\[\begin{equation} t = \frac{\overline{X}_{erkek}-\overline{X}_{kız}}{\sqrt{\frac{s^2_{erkek}}{n_{erkek}}+\frac{s^2_{kız}}{n_{kız}}}} \tag{2.6} \end{equation}\]
Gerçek değerler ile tahmin edilen değerlerin otalama ve varyanslarını kullanarak hesaplanacak iki t değerini de bulalım:
\[\begin{align} t_{gerçek} = \frac{35-15}{\sqrt{\frac{50}{2}+\frac{50}{2}}} && t_{tahmin} = \frac{35.59-14.41}{\sqrt{\frac{14.01}{2}+\frac{14.01}{2}}} \end{align}\]
İlgili hesaplamalar yapılırsa
\[\begin{align} t_{gerçek} = 2.82 && t_{tahmin} = 5.66 \end{align}\]
Görüleceği iki iki veri grubundan elde edilen t değerleri birbirinden farklı olmuştur. Gerçek (Gözlenen) varyansa dayalı hesaplama t değerini 2.82 olarak verirken tahmin edilen değerlerle yapılan hesaplama t değerini 5.66 olarak vermiştir. Bunun anlamlı şudur: Gözlenen varyansla yapılan hesaplamada kadınlar ve erkeklerin ortalamaları arasında fark vardır deme ihtimali, tahmin edilen verilerle yapılana oranla daha düşüktür. Bir başka deyişle tahmin edilen değerlerle yapılan analizde fark bulma ihtimali daha büyüktür. Bu noktada uygulanacak analizde varyanslara bir düzeltme uygulanarak yanlılığın giderilmesine çalışılması iyi bir çalışma konusu olabilir. Buradaki yanlılığın temel sebebi bu yazının en başında parantezlerle gösterilen regresyon varyansı ile gerçek varyansın birbirinden farklı olmasıdır. Gerçek varyans her zaman daha büyüktür ve ortalamalar arasındaki farkın anlamlılığını değerlendirirken farkın daha büyük bir varyans miktarına yol açarak t değerinin küçülmesine yol açar. Tahminlerin varyansı ise en çok gerçek varyans kadar çoğunlukla da ondan daha küçük olur. Bu haliyle ortalamalar arasındaki farkın daha küçük bir varyansa bölünmesi daha büyük bir t değerine yol açar. Ayrıca burada t değerleri arasındaki fark 2 kat gözlendi. Bunun olası diğer durumlarda nasıl bir dağılım sergilediği de iyi bir çalışma konusudur. Ayrıca regresyonun karşılaştırılacak gruplar için ayrı ayrı uygulanıp ardından ortalamaların karşılaştırılması da iyi bir çalışma konusu olabilir.